Chord Llama
Fine-tuning Llama for sheet music generation.
Introduction
Large Language Models (LLMs) have recently reached a critical mass in the public eye,
where everyone is trying to apply the technology to any problem they can think of.
They have been further trained, or fine-tuned, for a variety of use cases, be it for
business, software development, or speaking languages outside their original training
data. At the time, I had recently learned about MusicXML
which is the format used for sheet music. An application like MuseScore
is used to write music sheets for musicians and saves the work to a .MXL file so it can be
redistributed and edited without the pains of using a proprietary file type or making
the sheets by hand and scanning them with a printer. MusicXML has been a standard since 2004
and managed by W3C by 2015. As it is a pretty widely accepted standard, we looked into
understanding how an LLM like Llama could be fine-tuned on this data to continue existing music
or generate its own.
Music generation in the AI world is actually not a new concept. MuseFormer was released by Microsoft in 2022 and applies the transformer architecture to music. In their work, each concept like tempo, beat, pitch, and duration is a separate token. The attention mechanism has two stages the fine-grained attention only attends to the elements in the same bar, while the coarse-grained attention only attends to the summary of other bars. This allows it to be aware of the entire song without saving all of it in the context length.
An issue we saw with models like MuseFormer is that the model required a significant amount of technical knowledge to set up. This creates a barrier for entry that is non-existent with the flurry of open-source tools anyone can use to run LLMs on their machine. By instead fine-tuning Llama as a base of our project, while we would not have the tokenizer or architecture built for this use case, it would be able to run on any machine, easing the availability to end users greatly.
Data Collection
One of the more prevalent issues in AI training has been training on copyrighted material. We wanted to make sure that we did not fall into a legal grey area with the existence of this model, and to solve this we were able to get our sources from classical works in the public domain. Our first source was MScoreLib which was a project that scanned classical works into MusicXML using automated tooling. The second source was Wikifonia which was an online encyclopedia for public domain sheet music.
Data Cleaning & Preparation
Cleaning the data to get it into a usable form for Llama is what took up the majority of my time in this project.
The first thing I saw as a problem was the context size of Llama 3. Unlike 3.1’s 128k context size, Llama 3 had only 4k tokens to use. Many special characters that XML uses take up their own token. XML, and MusicXML especially, are very verbose standards, making it hard to fit much within the context size. The first thing I wanted to do was remove the lyrics and all the unnecessary tags in the file that did not affect the end appearance of the sheet music or were too rare to be learned by the model. This required going over the full MusicXML specification and creating lists for all of the elements and attributes that should either be removed or kept in the file. MusicXML allows to adjust the size and color of text, making pixel-level adjustments on the location of the note, and many more attributes that do not affect the appearance or sound of the file when played.
Removing all unnecessary elements was still not enough for most songs to fit within the 4k context length.
To further condense the music, we decided to convert the XML to YAML format. We decided on YAML as it
has been shown to be more token efficient and boost the performance of models
Doing this required us to index each musical part with a00_ where a was necessary because the program
could not handle YAML starting with a number and 00 was the number of the musical part. YAML is
commonly used for config files and is not intended for this use case at all. In practice though, this was
exactly what we needed to get the format small enough to pass in multiple staves to train the model on.
To visualize how much we condensed the format, on the left is an example of three notes of MusicXML, and on the right are the same three notes after our cleaning that we would send to the model.
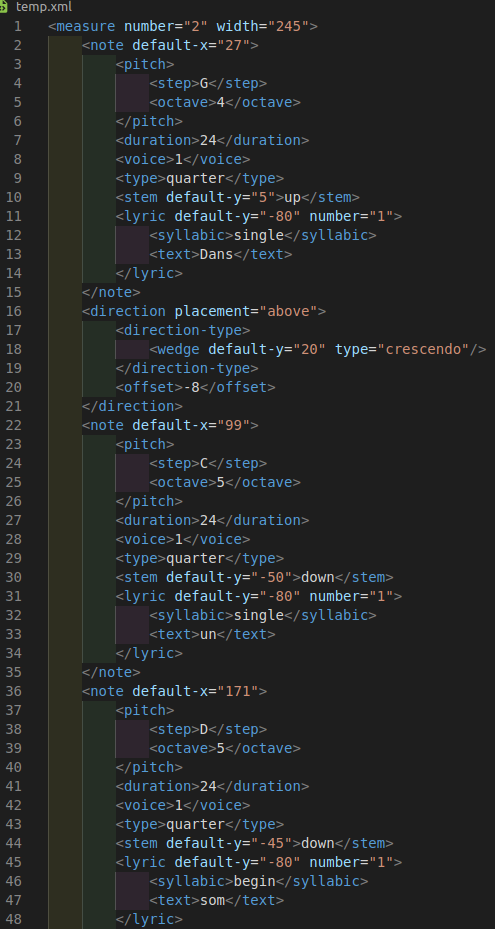
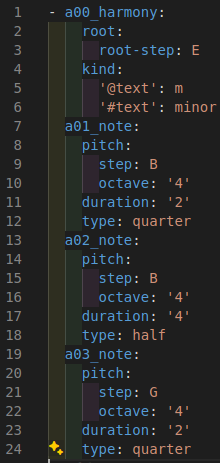
Additionally, we needed to be able to undo the YAML conversion so that we can verify that our steps worked and once the model is outputting new data in this format we can turn it into MusicXML to be viewed and listened to.
Finally, we needed to split the songs to fit inside the 4k token limit. We split each song into even chunks of up to 3500 tokens and put half of each in the input and output columns. We put the data in JSON Lines to be used for training and uploaded to HuggingFace.
The cleaned data in our format is available on HuggingFace along with the notebook used to create it: https://huggingface.co/datasets/Chord-Llama/chord_llama_dataset
Fine-Tuning
To train, the technical process we used was Low-Rank Adaptation (LoRA). LoRA works by adding small, adjustable components to each layer of the model, leaving the original model unchanged. Instead of using a single delta matrix, LoRA employs two matrices to reduce the dimensionality. Because there are fewer calculations and memory needed, the fine-tuning process is much faster. Additionally, this method also typically produces higher-quality results than normal fine-tuning.
We used Unsloth to help us fine-tune with LoRA. Unsloth allowed us to easily configure many parameters in training, as well as connect with Weights & Biases to record all of our tests. We were able to optimize scheduling, learning rate, weight decay, batch size, and gradient accumulation steps.
Our final dataset had almost 100k rows of training data, which we knew was more than enough for our purposes. To start, we trained on 10k samples but quickly found that this much training overfit the model, and it would be better to pick out a smaller sample size. The model did not improve after 1k samples, so we ended up training with 1.6k samples.
Optimization and Publishing
Just because a model is fine-tuned it does not mean that it is able to be used. After training, the model
is split across multiple .safetensor files. While this is useful for further development, for creating an
end-user application, it needs to be in a format that optimizes for inference. This often means converting
the checkpoint into GGUF, which is a standard .bin file that is
optimized for quick loading and saving and is standard for locally hosted inference applications. This was done
using llama.cpp. Quantizing the model to four-bit precision allowed it to
be run on the laptop for presenting the work, so we did that as well. I was able to publish this model on
Ollama for anyone to use.
The final component of the project was creating a small web application to show the model working. I decided that I wanted to use Flask for the backend and React for the front end, both new to me. While it was not the prettiest, it showed that from the data I put in, it was able to generate the music in real-time for the audience to see. It was unfortunately limited to the YAML, rather than converting back into MusicXML, but the result was more than enough to prove the functionality of the project.
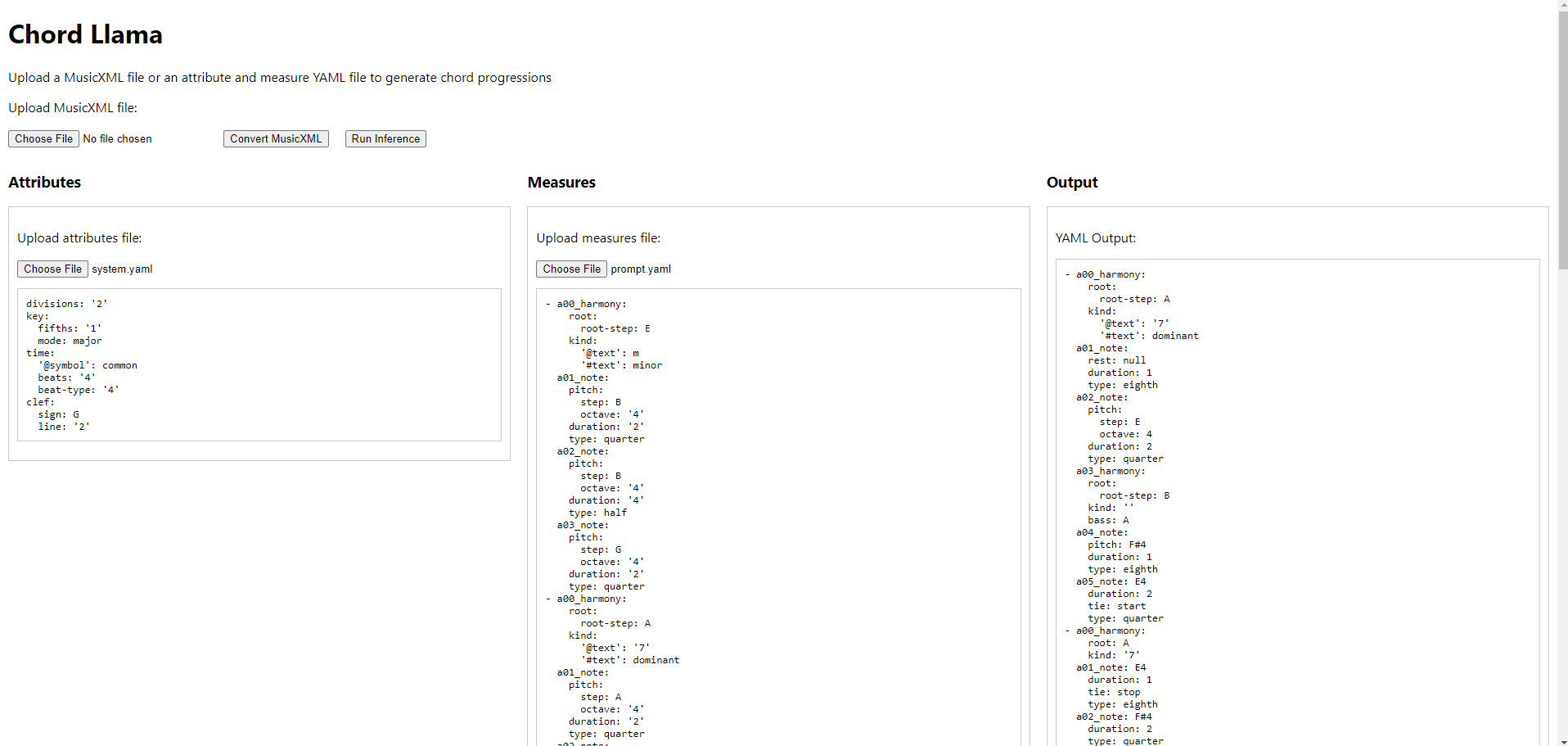
Conclusion
I loved the idea and our work in Chord Llama. I feel that with some more work and modern LLM technology, we could have had an LLM capable of generating good music that solved the goals we set for this project. Working with the unique problem of fitting MusicXML within a limited token context is exactly the fun and creative type of solution I love working on in software development.
Here are the links to the project. In addition, this project was part of my time at San Jose State University, and my partner and I wrote up a report at the end of the semester that you can read below for more information.
- Web Project on GitHub: https://github.com/Chord-Llama/Chord-Llama
- HuggingFace: https://huggingface.co/Chord-Llama